今天要介紹這兩個sklearn的方法
也是資料前處理常用到的
LabelEncoder:
就如同字面上意思,會將標籤做編碼
當我們想把一筆資料拿去train時,必須將所有的值都轉成數字,這樣電腦才能看懂,因為像是字串此類型的資料是無法直接拿下去train,而有時因為資料眾多將每個字串都轉成數字的工作將會變得耗時又繁瑣。
LabelEncoder就能快述的幫助我們做到快述的編碼
import方式:
我先建立一個示範資料
使用方式:
將LabelEncoder方法指派給一個變數
之後使用fit_transform後方填入要encoder的值
輸出結果:
同為apple的字串被編為0、banana為1、orange為2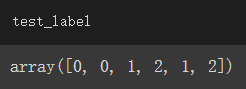
train_test_split:
快速的將資料分為訓練集和驗證集
import方式:
使用方式:
train_test_split後方參數第一個為特徵值、第二個target、第三個是要分成的比例
之後會回傳四個值 順序為訓練集特徵值、驗證集特徵值、訓練集target、驗證集traget
使用範例:
我使用在Titanic資料集,train_set總共有891筆資料 根據test_size=0.1
所以分成801筆與90筆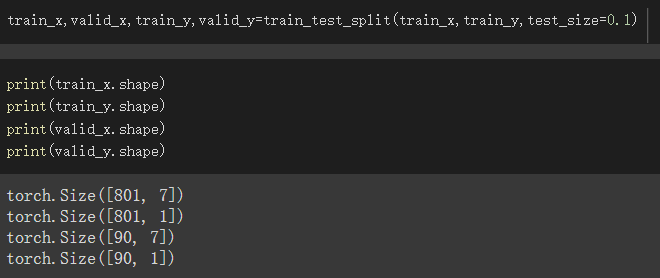


 iThome鐵人賽
iThome鐵人賽